scrapy-redis 实现分布式爬虫
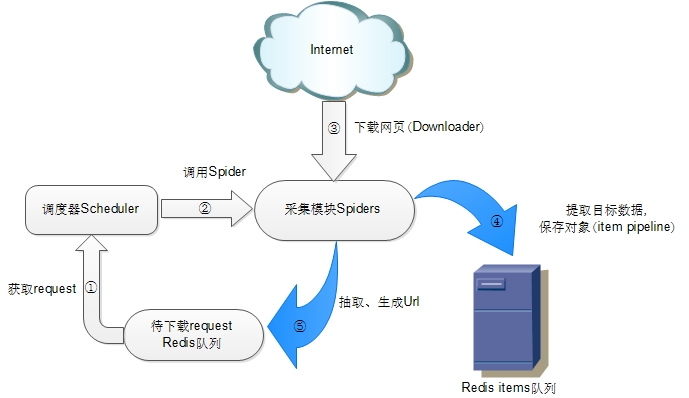
scrapy-redis 架构
1,安装scrapy-redis
pip install scrapy-redis
2,启用settings.py里面的组件
注意settings里面的中文注释会报错,换成英文
# 启用在redis中调度存储请求队列。
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 不要清理redis队列,允许暂停/恢复爬网。
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,默认是按照优先级排序
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# 可选的先进先出排序
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue'
# 可选的后进先出排序
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack'
# 只在使用SpiderQueue或者SpiderStack是有效的参数,,指定爬虫关闭的最大空闲时间
SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 指定RedisPipeline用以在redis中保存item
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400
}
# 指定redis的连接参数
# REDIS_PASS是我自己加上的redis连接密码,需要简单修改scrapy-redis的源代码以支持使用密码连接redis
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#REDIS_URL = 'redis://user:pass@hostname:9001'
#REDIS_PARAMS['password'] = 'itcast.cn'
LOG_LEVEL = 'DEBUG'
DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'
#The class used to detect and filter duplicate requests.
#The default (RFPDupeFilter) filters based on request fingerprint using the scrapy.utils.request.request_fingerprint function. In order to change the way duplicates are checked you could subclass RFPDupeFilter and override its request_fingerprint method. This method should accept scrapy Request object and return its fingerprint (a string).
#By default, RFPDupeFilter only logs the first duplicate request. Setting DUPEFILTER_DEBUG to True will make it log all duplicate requests.
DUPEFILTER_DEBUG =True
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate, sdch',
}
代理的中间件
class ProxyMiddleware(object):
def __init__(self, settings):
self.queue = 'Proxy:queue'
# 初始化代理列表
# self.r = redis.Redis(host=settings.get('REDIS_HOST'),port=settings.get('REDIS_PORT'),db=1,password=settings.get('REDIS_PARAMS')['password'])
self.r = redis.Redis(host=settings.get('REDIS_HOST'), port=settings.get('REDIS_PORT'), db=1)
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def process_request(self, request, spider):
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
if proxy['user_pass'] is not None:
#request.meta['proxy'] = "http://YOUR_PROXY_IP:PORT"
request.meta['proxy'] = "http://%s" % proxy['ip_port']
#proxy_user_pass = "USERNAME:PASSWORD"
encoded_user_pass = base64.encodestring(proxy['user_pass'])
request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass
print("********ProxyMiddleware have pass*****" + proxy['ip_port'])
else:
#ProxyMiddleware no pass
print(request.url, proxy['ip_port'])
request.meta['proxy'] = "http://%s" % proxy['ip_port']
def process_response(self, request, response, spider):
"""
检查response.status, 根据status是否在允许的状态码中决定是否切换到下一个proxy, 或者禁用proxy
"""
print("-------%s %s %s------" % (request.meta["proxy"], response.status, request.url))
# status不是正常的200而且不在spider声明的正常爬取过程中可能出现的
# status列表中, 则认为代理无效, 切换代理
if response.status == 200:
print('rpush',request.meta["proxy"])
self.r.rpush(self.queue, request.meta["proxy"].replace('http://',''))
return response
def process_exception(self, request, exception, spider):
"""
处理由于使用代理导致的连接异常
"""
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
request.meta['proxy'] = "http://%s" % proxy['ip_port']
new_request = request.copy()
new_request.dont_filter = True
return new_request
All posts
Other pages